How to do web scraping in PHP
In this tutorial, we will develop a PHP web scraper that will grab the top 5 job listing from Craiglist's website (New York City accounting/finance section). Through this tutorial, we want to teach you how to write a PHP web scraper to fit your own purpose.
Disclaimer: please do not use web scraping techniques to do things that are illegal, please consult with your lawyer before you do any web scraping on a large scale.
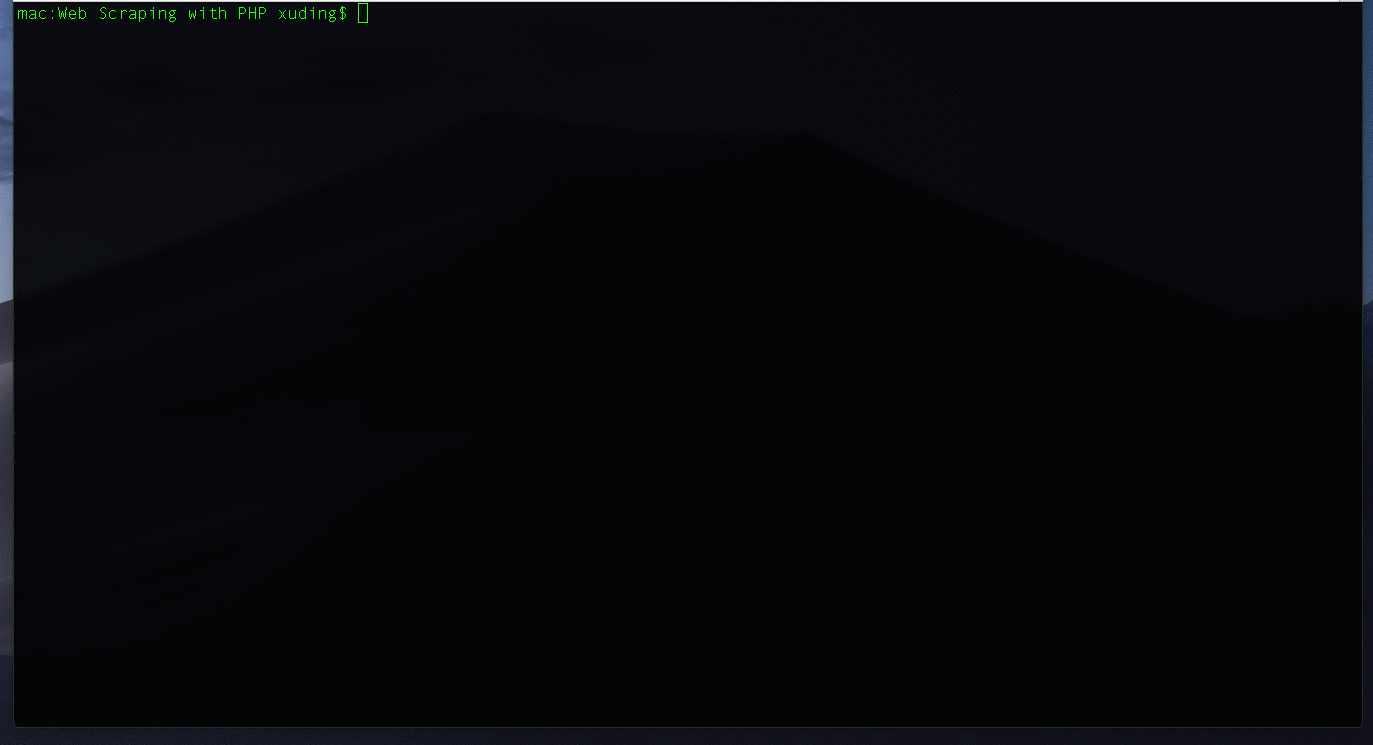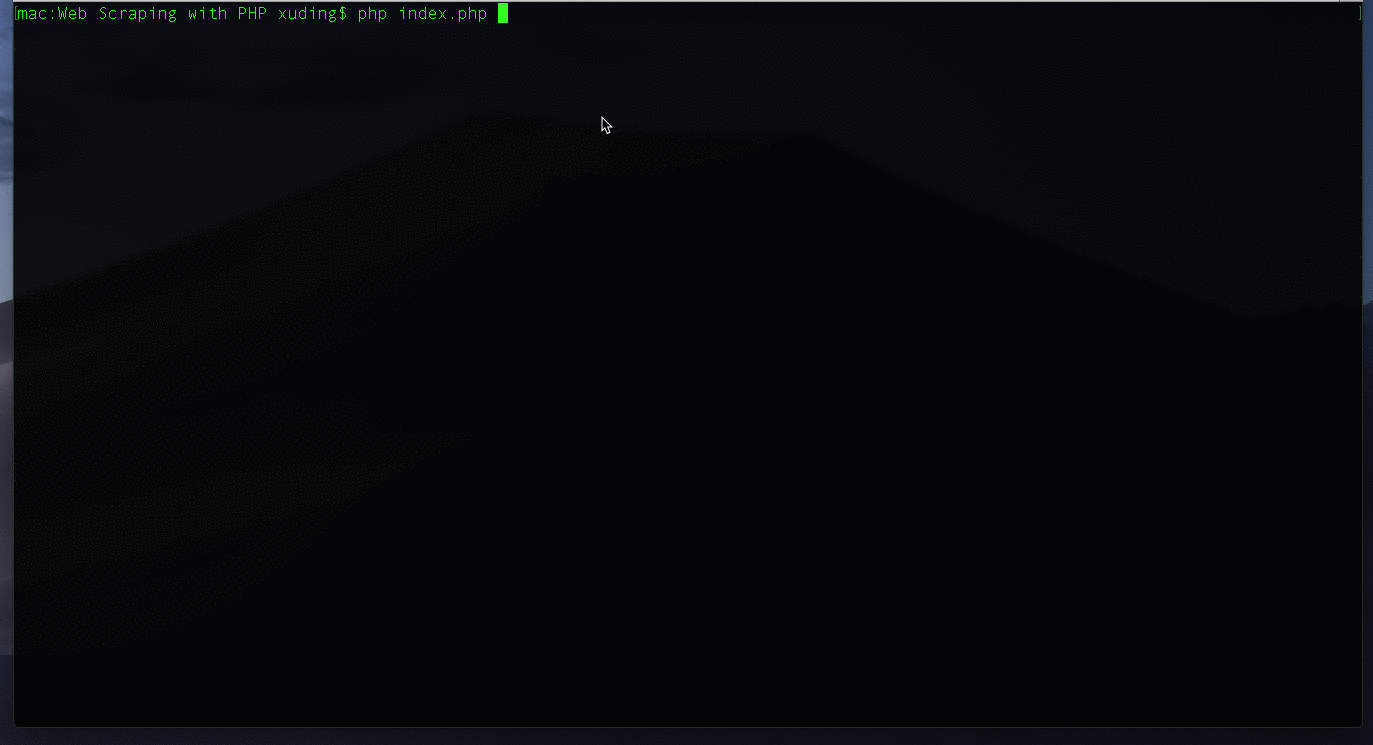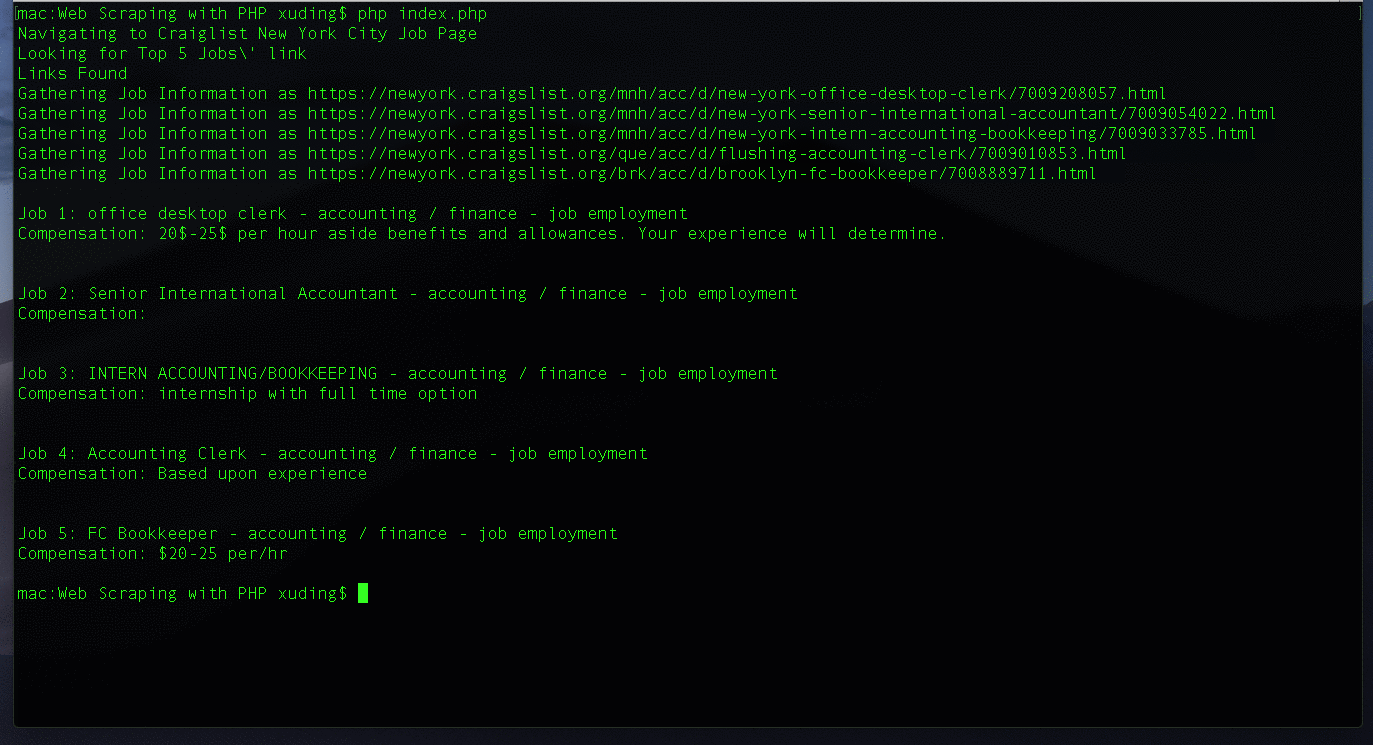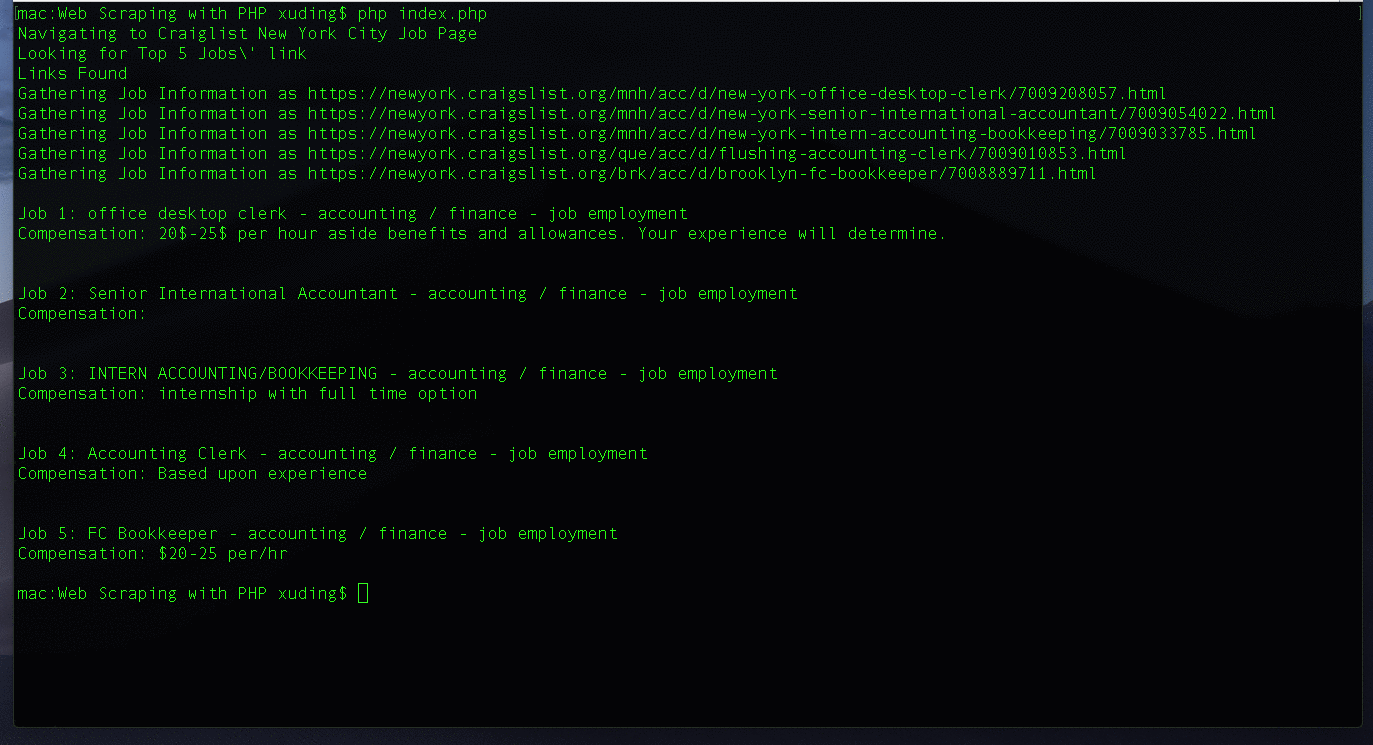
After this tutorial, you will build a web scraper, that works like something shown below:
Install the packages
We will be using a PHP package(voku/simple_html_dom) that handles HTML page parsing for us and we will use Composer to install any packages we need.
Run the command below to install voku/simple_html_dom:
composer require voku/simple_html_dom
Create a file index.php and include the package we have installed above, meanwhile include the Composer autoloader file:
require_once 'vendor/autoload.php';
use voku\helper\HtmlDomParser;
Find top 5 links
The first thing we will do is to navigate to the target page and get the top 5 job posting from that page.
The code as shown below does mention above:
$link = 'https://newyork.craigslist.org/d/accounting-finance/search/acc/';
echo "Navigating to Craiglist New York City Job Page \n";
$linkContent = HtmlDomParser::file_get_html($link);
echo "Looking for Top 5 Jobs\' link\n";
$jobLinks = findTop5JobsLinks($linkContent);
if (empty($jobLinks)) {
echo "Link not found\n";
exit();
}
The HtmlDomParser class is a powerful PHP class that can parse HTML content using any CSS selector.
We have not yet implemented the function findTop5JobLinks() yet, let's do so:
function findTop5JobsLinks(\voku\helper\HtmlDomParser $dom)
{
$result = [];
$jobs = $dom->find('.result-title');
for ($i = 0; $i < sizeof($jobs) && $i < 5; $i++) {
$result[] = $jobs[$i]->getAttribute('href');
}
return $result;
}
As you can see, we have manually checked the page's source code, that is why we know we can use the '.result-title' selector:
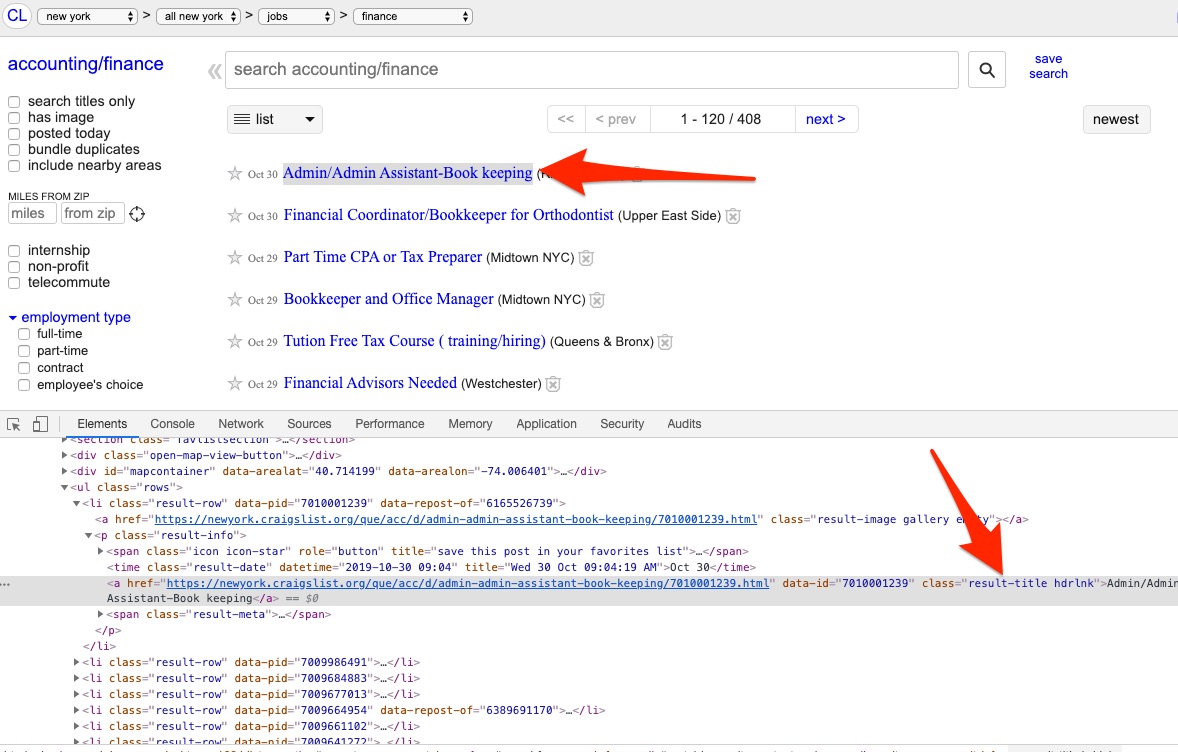
Gather job information
Now we have obtained the top 5 links, we need to instruct our scraper to navigate to those links and get its information(title and compensation).
Let's write the code to do so:
echo "Links Found\n";
$jobs = array_map(function ($jobLink) {
return gatherJobInfo($jobLink);
}, $jobLinks);
foreach ($jobs as $i => $job) {
echo "\n";
echo "Job " . ($i + 1) . ": " . $job['title'] . "\n";
echo "Compensation: ". $job['compensation'] . "\n\n";
}
We are using array_map to turn links to its information. But we have not yet implemented the function gatherJobInfo yet. Let's do so:
function gatherJobInfo($link)
{
echo "Gathering Job Information as $link\n";
$content = HtmlDomParser::file_get_html($link);
$title = $content
->findOne('title')
->innerText();
$compensation = $content
->findOne('.attrgroup')
->findOne('span');
if ($compensation->findOneOrFalse('b')) {
$compensation = $compensation->findOne('b')->innerText();
} else {
$compensation = $compensation->innerText();
}
return [
'title' => $title,
'compensation' => $compensation
];
}
Here again, we have used a couple of CSS selectors to help us find the information. How did we find to know the CSS selectors are there? Similar to the previous step, we manually checked.
Final
Now we have a nice web scraper that gathers the top 5 accounting/finance jobs from Craiglist's website. It might not be super useful, but it should teach you how to build something useful by yourself.
Here is the complete code:
<?php
require_once 'vendor/autoload.php';
use voku\helper\HtmlDomParser;
$link = 'https://newyork.craigslist.org/d/accounting-finance/search/acc/';
echo "Navigating to Craiglist New York City Job Page \n";
$linkContent = HtmlDomParser::file_get_html($link);
echo "Looking for Top 5 Jobs\' link\n";
$jobLinks = findTop5JobsLinks($linkContent);
if (empty($jobLinks)) {
echo "Link not found\n";
exit();
}
echo "Links Found\n";
$jobs = array_map(function ($jobLink) {
return gatherJobInfo($jobLink);
}, $jobLinks);
foreach ($jobs as $i => $job) {
echo "\n";
echo "Job " . ($i + 1) . ": " . $job['title'] . "\n";
echo "Compensation: ". $job['compensation'] . "\n\n";
}
function gatherJobInfo($link)
{
echo "Gathering Job Information as $link\n";
$content = HtmlDomParser::file_get_html($link);
$title = $content
->findOne('title')
->innerText();
$compensation = $content
->findOne('.attrgroup')
->findOne('span');
if ($compensation->findOneOrFalse('b')) {
$compensation = $compensation->findOne('b')->innerText();
} else {
$compensation = $compensation->innerText();
}
return [
'title' => $title,
'compensation' => $compensation
];
}
function findTop5JobsLinks(\voku\helper\HtmlDomParser $dom)
{
$result = [];
$jobs = $dom->find('.result-title');
for ($i = 0; $i < sizeof($jobs) && $i < 5; $i++) {
$result[] = $jobs[$i]->getAttribute('href');
}
return $result;
}
Hope you have enjoyed reading this tutorial. Sharing is caring, do share this tutorial if you have learned something from it.